BespON – Bespoken Object Notation
BespON is a configuration language focused on concise syntax, superior string and number support, and lossless round-tripping.
-
Multi-paradigm – Do you like braces, brackets, and explicit quotation marks, with no significant whitespace? Would you rather leave out some quotation marks and use significant indentation instead of braces and brackets? Do you prefer INI-style sections, with no braces or brackets and no indentation? BespON supports all three styles.
-
Strings and numbers – Literal and escaped multiline strings that are ideal for storing template text. Floats and integers, in multiple bases, with Infinity and NaN to support IEEE 754 floats.
-
Lossless round-tripping – Designed to be loaded by a computer, modified, and then saved while retaining exact layout, including comments.
Take a look:
Why?

Now that the requisite XKCD reference is out of the way, why BespON?
- Comments. Instead of not having comments. Normal comments aren't uniquely associated with individual data elements (or necessarily with data at all), so BespON also provides doc comments. Only one doc comment is allowed per data element. This brings the possibility of round-tripping with arbitrary data manipulation while retaining all (doc) comments.
- Trailing commas. No more errors from things like
{key = value,}. - Unquoted strings. But only identifier-style strings, and only strings
that do not match keywords words like
trueunder any capitalization. - Consistent reserved words.
trueis always boolean True. It isn't boolean True or the string "true" depending on whether it happens to appear as a dict key or as a dict value. - Multiline strings that take into account the needs of storing template text. Indentation is preserved relative to delimiters. Leading/trailing whitespace is obvious, since it's inside delimiters. Opening delimiters are different than closing delimiters, so it's easy to distinguish the start of a multiline string from the end when working with long templates. Both literal multiline strings and multiline strings with backslash escapes are supported.
- Integers. And integers with various bases (decimal, hex, octal, binary).
- Full IEEE 754 floating point compatibility with Infinity and NaN, including hex floats for cases when rounding errors aren't acceptable.
- Immutable data object model. Duplicate keys in dicts are invalid and must result in an error.
- A small number of special characters. Every ASCII punctuation character does not have its own, special meaning. No constant wondering about what is allowed unquoted, and if it will appear as itself or something else.
- Sections and key paths for conveniently representing nested data structures, without ending up with bracket soup or half a page width of indentation.
- Inheritance. Shared default or fallback values only need to be specified once.
- Optional support for aliases and circular references to avoid data duplication and allow complex data relationships.
- Round-trip support. Programmatically replace keys or values, or access or even modify comments – while keeping all layout and comments.
- "Acceptable" performance even when completely implemented in an interpreted language (see the benchmarks).
Getting started
A Python implementation is available now. It may be installed via
pip install bespon
The bespon package for Python supports loading and saving data. There is
also round-trip support for modifying keys and values while keeping formatting
and comments. For example,
>>> import bespon
>>> ast = bespon.loads_roundtrip_ast("""
key.subkey.first = 123 # Comment
key.subkey.second = 0b1101
key.subkey.third = `literal \string`
""")
>>> ast.replace_key(['key', 'subkey'], 'sk')
>>> ast.replace_val(['key', 'sk', 'second'], 7)
>>> ast.replace_val(['key', 'sk', 'third'], '\\another \\literal')
>>> ast.replace_key(['key', 'sk', 'third'], 'fourth')
>>> print(ast.dumps())
key.sk.first = 123 # Comment
key.sk.second = 0b111
key.sk.fourth = `\another \literal`
This illustrates several of the round-trip capabilities.
- Comments and layout are preserved exactly.
- Key renaming works with key paths. Every time a key appears in key paths, it is renamed.
- When a number is modified, the new value is expressed in the same base as the old value.
- When a quoted string is modified, the new value is quoted in the same style as the old value (at least to the extent that this is practical).
- As soon as a key is modified, the new key must be used for further modifications. The old key is invalid.
The development version of the bespon
package already provides several additional round-trip features that are
being refined for the next release. For example,
>>> ast = bespon.loads_roundtrip_ast("""
### key doc comment ###
key = # key trailing comment
value # value trailing comment
""")
>>> ast['key'].key = 'new_key'
>>> ast['new_key'].key_doc_comment = ' new key doc '
>>> ast['new_key'].key_trailing_comment = ' key trailing...'
>>> ast['new_key'].value = 'val'
>>> ast['new_key'].value_trailing_comment = ' val trailing...'
>>> print(ast.dumps())
### new key doc ###
new_key = # key trailing...
val # val trailing...
There is a syntax highlighting extension for Visual Studio Code. It has been posted to the Visual Studio Marketplace, so it can be installed with the built-in extension manager.
There is a language-agnostic test suite, which the Python implementation passes.
Benchmarks
One of the goals for BespON is "acceptable" performance even when completely
implemented in an interpreted language. So far, the pure Python
implementation is promising. It contains minimal optimizations (avoidance of
globals, use of __slots__), and has significant overhead since it saves
detailed source information about each data object to support round-tripping
and to provide detailed error messages. In spite of this, when decoding under
CPython it can be only about 50% slower than PyYAML using LibYAML, the
C implementation of YAML. Under PyPy, the pure Python
implementation can actually be significantly faster than LibYAML – it can
even be within an order of magnitude of
json's speed under CPython.
The decoding benchmark data below was created using the
BespON Python benchmark code
under Ubuntu 16.04. All data was collected with Anaconda Python 3.6.1
(64-bit) except that designated with "PyPy," which used PyPy3.5 5.7.1
(64-bit). PyYAML was tested with its C library implementation (CLoader)
when available. Package versions were bespon 0.2.0, PyYAML 3.12,
toml 0.9.2, and pytoml 0.1.13, along with the built-in json module.
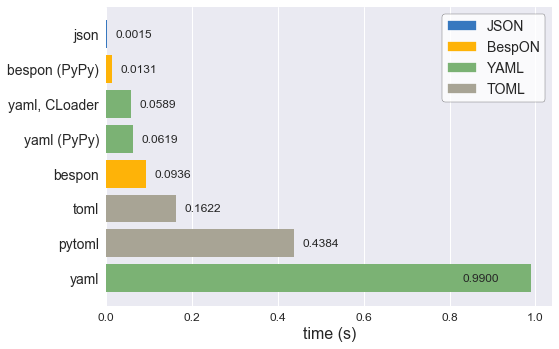
The benchmark data should not be interpreted as making a definitive statement about BespON performance under Python, since that will depend on the nature of specific data sets and the features used to represent them. Nevertheless, it does indicate that BespON performance can be competitive with that of similar formats.
Stability
While changes are still possible, all current features are expected to be stable. Development is currently focused on refining existing features and adding more powerful round-trip functionality.
Specification
A brief overview is currently available. More
technical details are in the Python implementation, particularly in
grammar.py and re_patterns.py. A more formal, more detailed
specification will follow as soon as the Python implementation is refined
further.